Apache Spark是一个效率极高的大数据处理引擎
各种快
在内存中运行程序比Hadoop MapReduce快100倍,在磁盘中快10倍
Spark使用先进的DAG(Directed Acyclic Graph)执行引擎并且支持循环数据流和内存计算。
引用官网的一张图:
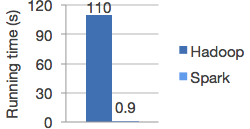
各种好用
在Java,Scala,Python等语言中非常简便快捷地编写程序
Spark提供了80多种操作指令,能够非常简单的开发并行应用程序,并且能在不同语言之间交互使用。
例如Spark’s Python实现的Word count:
1 | text_file = spark.textFile("hdfs://...") |
各种概要
包括SQL处理,流处理和复杂的数据分析
Spark提供了非常丰富的库,包括SQL出库库SQL and DataFrames,机器学习库MLlib,图形处理GraphX和流处理Spark Streaming,你可以在一个应用里无缝的整合这些库。
Spark的栈库: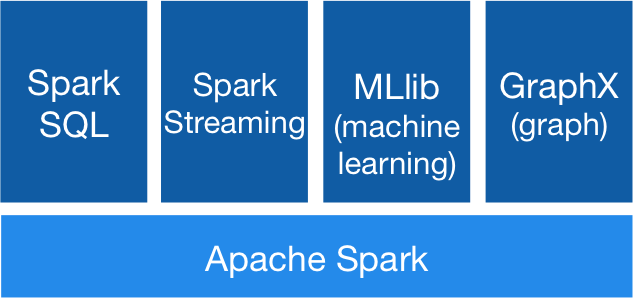
各种运行
Spark可以运行在Hadoop,Mesos,standalone or cloud,可以访问各种不同的数据源,如:HDFS,Cassandra,HBase以及S3
可以在EC2上运行Spark的 standalone cluster mode,也可以在Hadoop YARN 或 Apache Mesos上运行,可以访问各种类型的数据如: HDFS, Cassandra, HBase, Hive, Tachyon。
spark-runs-everywhere: